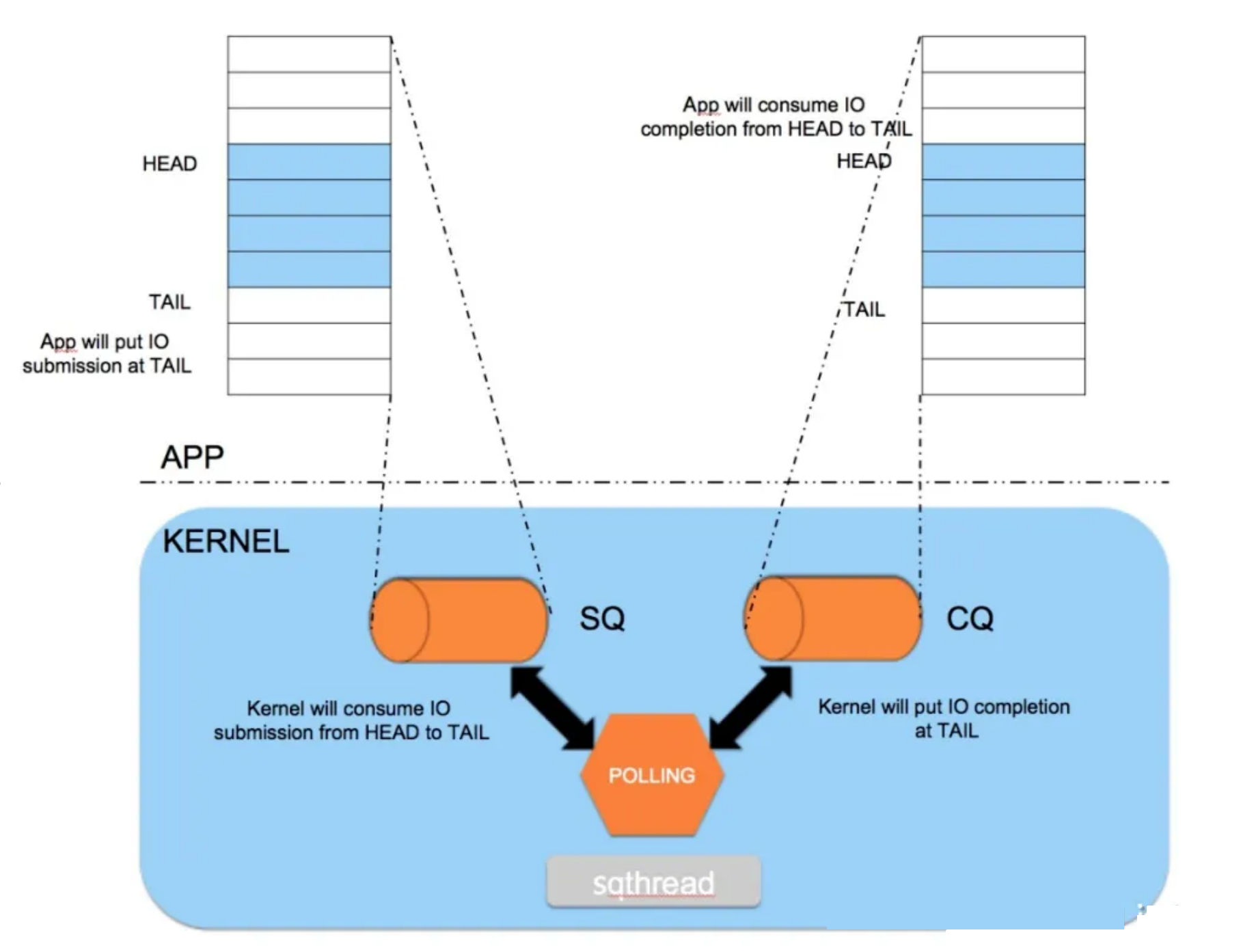
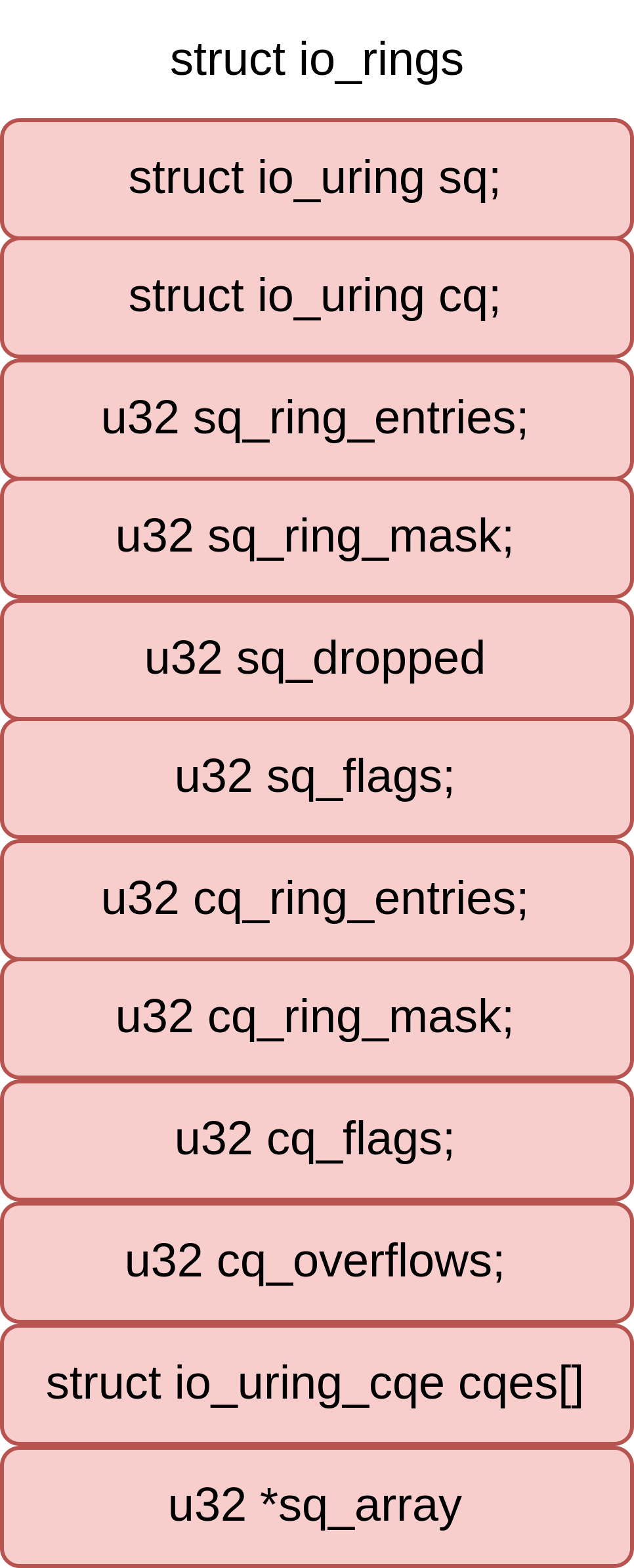
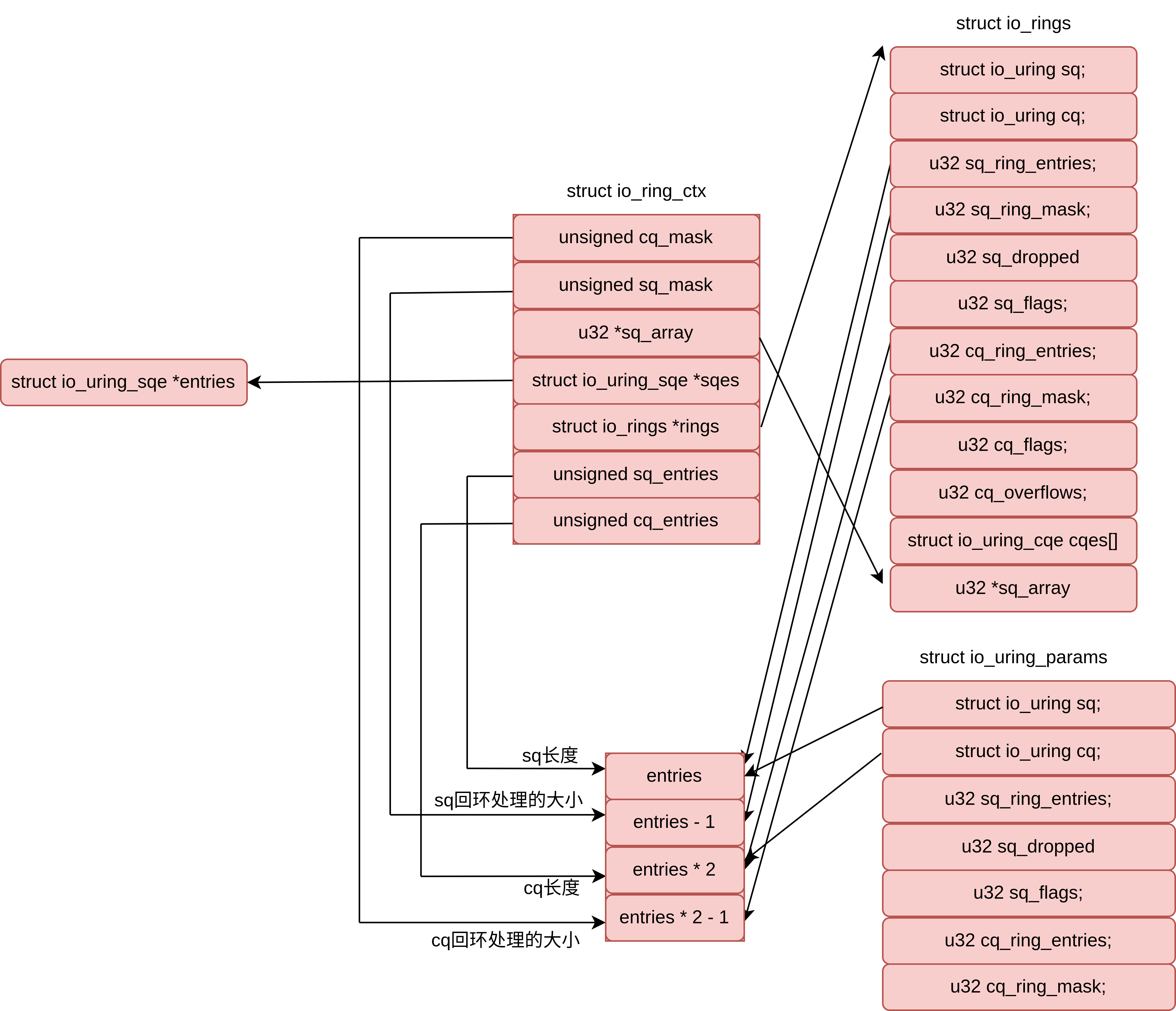
/* * This data is shared(from kernel) with the application through the mmap at offsets * IORING_OFF_SQ_RING and IORING_OFF_CQ_RING. * * The offsets to the member fields are published through struct * io_sqring_offsets when calling io_uring_setup. */ structio_rings { /* * Head and tail offsets into the ring; the offsets need to be * masked to get valid indices. * * The kernel controls head of the sq ring and the tail of the cq ring, * and the application controls tail of the sq ring and the head of the * cq ring. */ structio_uringsq, cq; /* * Bitmasks to apply to head and tail offsets (constant, equals * ring_entries - 1, i.e., sq_ring_mask = sq_ring_entries - 1, cq_ring_mask = cq_ring_entries - 1) */ u32 sq_ring_mask, cq_ring_mask; /* Ring sizes (constant, power of 2) */ u32 sq_ring_entries, cq_ring_entries; /* * Number of invalid entries dropped by the kernel due to * invalid index stored in array * * Written by the kernel, shouldn't be modified by the * application (i.e. get number of "new events" by comparing to * cached value). * * After a new SQ head value was read by the application this * counter includes all submissions that were dropped reaching * the new SQ head (and possibly more). */ u32 sq_dropped; /* * Runtime SQ flags * * Written by the kernel, shouldn't be modified by the * application. * * The application needs a full memory barrier before checking * for IORING_SQ_NEED_WAKEUP after updating the sq tail. */ atomic_t sq_flags; /* * Runtime CQ flags * * Written by the application, shouldn't be modified by the * kernel. */ u32 cq_flags; /* * Number of completion events lost because the queue was full; * this should be avoided by the application by making sure * there are not more requests pending than there is space in * the completion queue. * * Written by the kernel, shouldn't be modified by the * application (i.e. get number of "new events" by comparing to * cached value). * * As completion events come in out of order this counter is not * ordered with any other data. */ u32 cq_overflow; /* * Ring buffer of completion events. * * The kernel writes completion events fresh every time they are * produced, so the application is allowed to modify pending * entries. */ structio_uring_cqecqes[] ____cacheline_aligned_in_smp; };
structio_ring_ctx { /* const or read-mostly hot data */ struct { unsignedint flags; unsignedint drain_next: 1; unsignedint restricted: 1; unsignedint off_timeout_used: 1; unsignedint drain_active: 1; unsignedint has_evfd: 1; /* all CQEs should be posted only by the submitter task */ unsignedint task_complete: 1; unsignedint lockless_cq: 1; unsignedint syscall_iopoll: 1; unsignedint poll_activated: 1; unsignedint drain_disabled: 1; unsignedint compat: 1;
/* submission data */ struct { structmutexuring_lock;
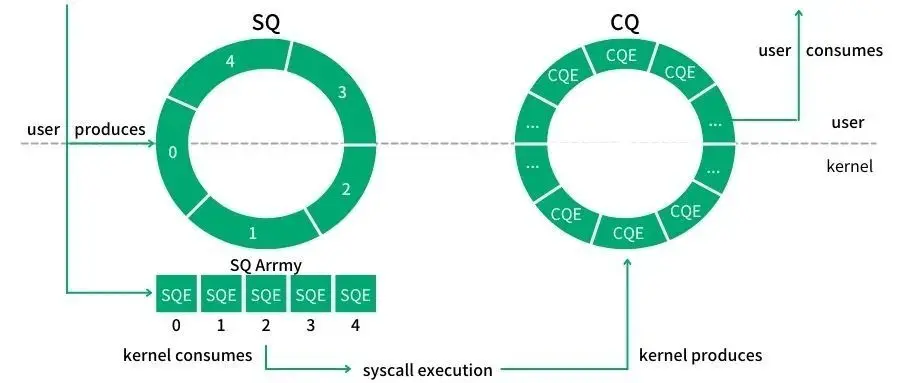
/* * Ring buffer of indices into array of io_uring_sqe, which is * mmapped by the application using the IORING_OFF_SQES offset. * * This indirection could e.g. be used to assign fixed * io_uring_sqe entries to operations and only submit them to * the queue when needed. * * The kernel modifies neither the indices array nor the entries * array. */ u32 *sq_array; // indices array structio_uring_sqe *sq_sqes; unsigned cached_sq_head; unsigned sq_entries;
/* * Fixed resources fast path, should be accessed only under * uring_lock, and updated through io_uring_register(2) */ structio_rsrc_node *rsrc_node; atomic_t cancel_seq; structio_file_tablefile_table; unsigned nr_user_files; unsigned nr_user_bufs; structio_mapped_ubuf **user_bufs;
/* * ->iopoll_list is protected by the ctx->uring_lock for * io_uring instances that don't use IORING_SETUP_SQPOLL. * For SQPOLL, only the single threaded io_sq_thread() will * manipulate the list, hence no extra locking is needed there. */ structio_wq_work_listiopoll_list; bool poll_multi_queue; } ____cacheline_aligned_in_smp;
struct { /* * We cache a range of free CQEs we can use, once exhausted it * should go through a slower range setup, see __io_get_cqe() */ structio_uring_cqe *cqe_cached; structio_uring_cqe *cqe_sentinel;
/* * If IORING_SETUP_NO_MMAP is used, then the below holds * the gup'ed pages for the two rings, and the sqes. */ unsignedshort n_ring_pages; unsignedshort n_sqe_pages; structpage **ring_pages; structpage **sqe_pages; };