io_uring api
api
数据结构定义好了,逻辑实现具体是如何驱动这些数据结构的呢?使用上,大体分为准备、提交、收割过程。
linux kernel仅仅提供了三个系统调用,简化了异步io的操作
1 | |
源码分析
io_uring_setup
简介
io_uring通过io_uring_setup完成准备阶段,初始化io_uring实例,包括
分配共享内存,该内存交由kernel管理
初始化各个数据结构,如io_ring_ctx、io_rings、两个io_uring(sq和cq分别有一个)
注册包含io_ring_ctx的文件,应用程序通过该文件的fd来获取io_ring_ctx,从而访问io_uring实例
处理应用程序指定的flags相关的事宜,如SQ thread
接口如下
1 | |
其中,比较重要的flags有
IORING_SETUP_IOPOLL
让内核采用 Polling 的模式收割Block层的请求。在收割IO时,以忙等待的方式,而不是异步中断通知(Interrupt Request)的方式,即应用程序需要不断调用io_uring_enter轮询设备来检查io是否完成。因此相比于IRQ,会消耗更多的cpu资源,但IO操作的延迟更低。该种方式需要依靠打开文件的时候,设置为 O_DIRECT 的标记。我没弄懂- 猜测:
- 在IOPOLL启用时,会依靠轮询的方式收割block层的请求
- 如果在IOPOLL开启后,SQPOLL也开启了,那么用户在收割完成事件时也不用阻塞了,SQ thread会处理该事情
IORING_SETUP_SQPOLL
- 内核额外启用一个内核线程,称为SQ线程。这个内核线程可以运行在某个指定的 core 上(通过 sq_thread_cpu 配置)。这个内核线程会不停的 Poll SQ,除非在一段时间内没有 Poll 到任何请求(通过 sq_thread_idle 配置),才会被挂起。SQ线程不仅会处理IO提交,也会处理IO完成事件
IORING_SETUP_SINGLE_ISSUER
- 只能有一个线程提交任务
IORING_SETUP_DEFER_TASKRUN
- 在异步任务中,可能存在这种情况:在异步IO任务A提交后,该任务会加入到task work queue中,当cpu正在运行某个非常重要的任务B时,IO任务A可能从 task work queue中被调度出来,挤掉任务B的执行,导致这个非常重要的任务B的执行延迟变大,即执行时间增加。通过在io_uring_setup中设置IORING_SETUP_DEFER_TASKRUN,使得我们可以在用户调用io_uring_enter,并且带上IORING_ENTER_GETEVENTS时,才开始执行这些异步任务,例如IO任务A。这样就避免这些异步任务中断其他正在运行的任务。
源码
io_uring_setup系统调用的过程就是初始化相关数据结构,建立好对应的缓存区,然后通过系统调用的参数io_uring_params结构传递回去,告诉核外环内存地址在哪,起始指针的地址在哪等关键的信息。
需要初始化内存的内存分为三个区域,分别是SQ,CQ,SQEs。内核初始化SQ和CQ,SQ和CQ都是ring,此外,提交请求在SQ,CQ之间有一个间接数组,即内核提供了一个Submission Queue Entries(SQEs)数组。
io_uring_setup的逻辑可以分为以下三部分
- 创建一个上下文结构io_ring_ctx用来管理整个会话。
- 根据io_uring_params->sq_off/cq_off偏移量来实现SQ和CQ内存区的映射
- 错误检查、权限检查、资源配额检查等检查逻辑。
1 | |
如下图所示,io_uring_setup的主要功能由以下四个函数提供
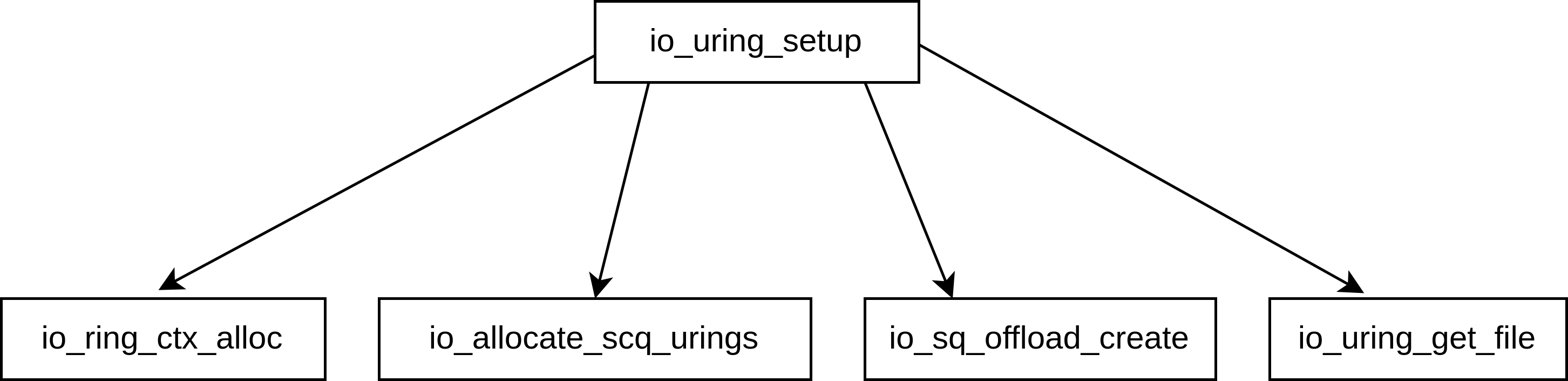
io_ring_ctx_alloc,主要用来申请空间,初始化列表头、互斥锁、自旋锁等结构
io_allocate_scq_urings,初始化整个
struct io_rings *rings,包括SQ/CQ头尾指针、SQE、CQESQ、CQ头尾指针以及CQE都在struct io_rings *rings结构体中SQE则是在struct io_ring_ctx *ctx结构体中
io_sq_offload_create,根据用户通过
io_uring_setup传递的flags来配置io_uring的运行方式io_uring_get_fd 将
struct io_ring_ctx *ctx暴露给用户态访问
io_sq_offload_create
1 | |
io_uring_enter
简介
通过使用io_uring_setup初始化的io_uring实例,io_uring_enter既可以提交IO请求,又可以收割IO完成事件。
1 | |
比较重要的flags如下
IORING_ENTER_GETEVENTS
- 设置该flag后,io_uring_enter会收割至少min_complete个完成事件,否则会阻塞。当to_submit也设置了时,io_uring_enter既可以提交IO请求,又可以收割IO完成事件
IORING_ENTER_SQ_WAKEUP
- 如果在io_uring_setup系统调用中,设置了**IORING_SETUP_SQPOLL **flag,即使用了SQ thread,那么sq ring中在长时间未有IO请求时,SQ thread会休眠,设置此flag后会唤醒SQ thread
IORING_ENTER_SQ_WAIT
- 在设置了IORING_SETUP_SQPOLL flag后,SQ thread会处理sqes上的IO请求,那么应用程序就不知道sqes中是否还有空闲位置来提交IO请求,因此有可能在通过io_uring_enter来提交IO请求时,sqes中并没有空闲位置,那么此时就需要等待,直到有IO请求被内核处理,留出来空闲位置后,io_uring_enter才能返回
IORING_ENTER_REGISTERED_RING
- 如果在多线程模式下,用io_uring_setup注册了一个io_uring实例,那么io_uring对应的file会被多个线程共享,因此在访问io_uring file对应的fd时,需要记录和设置其引用计数。例如,每次io_uring_enter前后都需要调用fdget/fdput,这样严重增大了开销。一种解决办法是将io_uring fd通过io_uring_register注册到current->io_uring_task->registered_rings中,之后便可通过该成员获取fd,不用处理fd的引用计数了。当启用此方法时,设置IORING_ENTER_REGISTERED_RING表示io_uring_enter中传入的fd不是真实的文件描述符,而是current->io_uring_task->registered_rings中的index。通过该index即可获取到对应的io_uring fd
源码
1 | |
io_uring_register
简介
主要用于注册/释放各种不同类型的缓冲区资源。通过提前注册这些缓冲区可以减轻后续每个 IO 的申请资源开销
1 | |
源码
1 | |