jump label
什么是jump label
在通常情况下,我们会使用分支语句来决定是否执行某个事件,例如
1
2
3
4
5
6bool keyfalse;
if (!key)
// do unlikely code
else
// do likely code
上述分支判断语句通常会被编译为mov, test, je的指令组合
在linux kernel中,启用jump label后,这类分支语句可以改写为
1
2
3
4
5
6DEFINE_STATIC_KEY_FALSE(key);
if (static_branch_unlikely(&key))
do unlikely code
else
do likely code
分支判断语句会被编译为jmp 0指令,消除了比较指令和分支指令
jump label的由来
由上面可知,jump label会消除比较指令和分支指令,因此适用于对同一条件的分支语句较多的情况。在linux kernel中,有一典型例子:tracepoint。tracepoint通常由条件判断语句实现,在每个tracepoint检查全局变量。看起来此类语句对整个程序的性能影响很小,其实不然,因为tracepoint出现的频率较高,并且全局变量会影响cache命中率。为了尽可能减少由于过多的条件判断语句带来的性能影响,linux kernel 引入了jump label。
jump label的实现原理
基本原理
在linux kernel中实现了static key,利用code patch技术在运行时修改代码段的指令。
具体实现
在编译条件判断语句时,往代码段中patch一条no-op指令
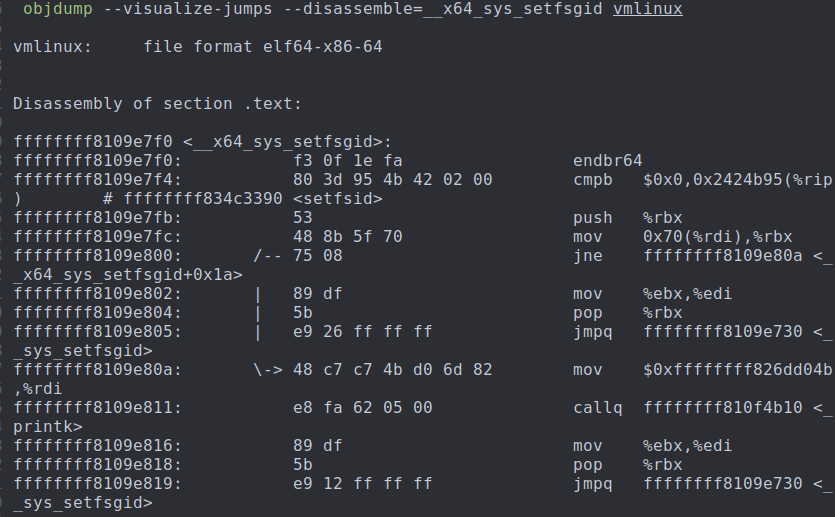
禁用jump label
1
2
3
4
5
6
7
8bool setfsid = false;
SYSCALL_DEFINE1(setfsgid, gid_t, gid)
{
if (setfsid) {
pr_info("hello\n");
}
return __sys_setfsgid(gid);
}
启用jump label
1
2
3
4
5
6
7
8
9DEFINE_STATIC_KEY_FALSE(setfsid);
SYSCALL_DEFINE1(setfsgid, gid_t, gid)
{
if (static_branch_unlikely(&setfsid)) { // static_branch_unlikely的意思是条件不会满足
pr_info("hello\n");
}
return __sys_setfsgid(gid);
}
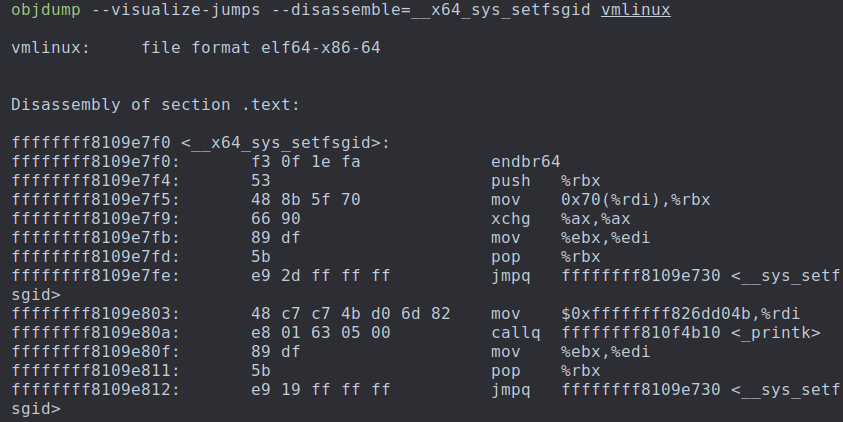
可以看出使用jump label后
1、cmpb + je 两条指令被替换为了-> xchg一条指令,这就是code patch
2、省去了8 + 2 - 2 = 8个字节
启用jump label,但是在分支语句中使用static_branch_likely时
1
2
3
4
5
6
7
8
9DEFINE_STATIC_KEY_FALSE(setfsid);
SYSCALL_DEFINE1(setfsgid, gid_t, gid)
{
if (static_branch_likely(&setfsid)) {
pr_info("hello\n");
}
return __sys_setfsgid(gid);
}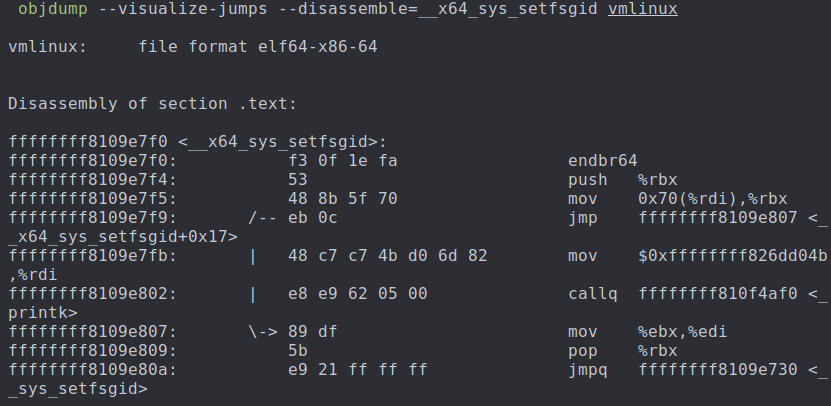
可以看出,无论在分支语句中使用static_branch_unlikely还是static_branch_likely,编译出的对应指令段中,都未出现比较指令,要么是no-op指令(xchg),要么是直接跳转指令(jmp),因此都可以消除分支指令带来的性能影响。
性能
启用jump label后,如下两点有性能优化
- 指令数减少
- 分支指令减少
参考static key的官方文档,对于如下代码
1 | |
启用jump label后,即性能提升(我并不了解这里的benchmark)为
- 动态指令数减少了0.2%
- 分支指令数减少了0.7%
- 运行周期数减少了2.8%